|
Título: Predicción de pacientes diabéticos. Preprocesado para Minería de Datos.
Autores: Ing. Rolando Acosta Sánchez. Dr. Alejandro Rosete Suárez. Lic. Alfredo Rodríguez Díaz.
La presente investigación expone el desarrollo de las fases de comprensión y preparación de los datos, dentro de la metodología para desarrollar procesos de Minería de Datos, CRISP-DM 1.0. Se refleja el caso práctico del trabajo con los datos asociados a encuestas realizadas con el objetivo de determinar factores influyentes en el padecimiento de diabetes. Como herramienta de apoyo para la descripción y comprensión de los datos se emplearon Microsoft Excel 2007 y WEKA 3.5.8. Palabras clave: Minería de Datos, KDD, Comprensión de Datos, CRISP-DM, Microsoft Excel 2007, WEKA, Diabetes. . Key words: Data Mining, KDD, data compression, CRISP-DM, Microsoft Excel 2007, WEKA, Diabetes.
Introducción
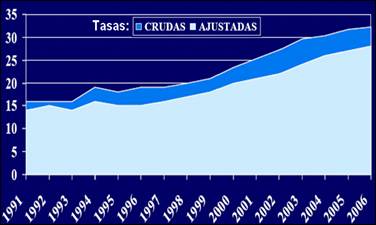
En nuestro país (Cuba) la diabetes es un problema creciente. La Figura 1 muestra el incremento que se ha producido en la cantidad de personas identificadas como diabéticas entre los años 1991 y 2006 5.
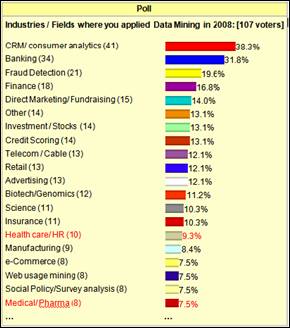
Figura. 1: Prevalencia de Diabetes Mellitus en Cuba. Tasas Crudas y Ajustadas por edad x 1000 habitantes 5. Desde épocas remotas, el estudio de los casos particulares de determinados padecimientos y características de los pacientes ha sido fundamental para el desarrollo de la medicina como ciencia. El estudio de casos particulares permite la generalización; así como encontrar síntomas o causas de enfermedades u otro tipo de padecimiento. Actualmente, con el surgimiento de la denominada era digital y el desarrollo de las nuevas técnicas de almacenamiento y recuperación de la información, el registro y análisis de los procesos que tienen lugar en una empresa o sector se ha visto particularmente potenciado. Una forma muy valiosa de análisis de información es la Minería de Datos. A pesar de la popularidad del término, “la Minería de Datos es sólo una etapa, si bien la más importante, de lo que se ha venido llamando el proceso de extracción de conocimiento a partir de datos. Este proceso consta de varias fases e incorpora muy diferentes técnicas de los campos del aprendizaje automático, la estadística, las bases de datos, los sistemas de toma de decisión, la inteligencia artificial y otras áreas de la informática y de la gestión de información.” 6 El proceso de extracción de conocimiento a partir de datos, en inglés Knowledge Discovery in Databases, KDD (o simplemente Minería de Datos, como comúnmente se le llama) ha sido definido de diferentes maneras por diversos autores. Sin embargo, todos refieren las mismas ideas. Por citar una de las definiciones, se puede entender la Minería de Datos como: “el proceso de descubrir conocimientos interesantes, como patrones, asociaciones, cambios, anomalías y estructuras significativas a partir de grandes cantidades de datos almacenadas en bases de datos, Data-Warehouses, o cualquier otro medio de almacenamiento de información.” 7 Uno de los campos en los que la Minería de Datos se está viendo cada día más utilizada es precisamente en la medicina. En una encuesta realizada por el portal para el análisis de datos KDnuggets, en diciembre de 2008, sobre las diversas áreas en las que se emplea la Minería de Datos, aparecen las aplicaciones en la medicina en los lugares 15, con un 9.3% de empleo (cuando se refiere al cuidado da la salud) y en el lugar 20, con un 7.5% de empleo (cuando se refiere a procesos farmacéuticos) 8. La Figura 2 muestra los resultados de la encuesta referida. Un análisis comparativo entre los resultados de la encuesta realizada en ese año (2008) y el anterior (2007), reflejó que en tanto las aplicaciones referidas a procesos farmacéuticos bajaron 1.9 puntos porcentuales, las aplicaciones al cuidado de la salud aumentaron 2.1 puntos porcentuales. Los resultados para el año 2007 pueden ser consultados en 9. Estos análisis evidencian el amplio uso que está teniendo la Minería de Datos en estas áreas, y su estabilidad de empleo.
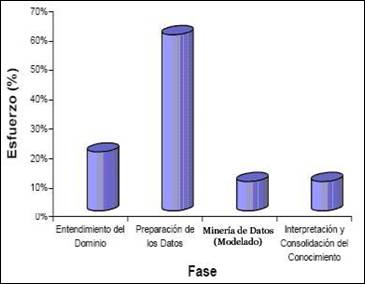
Figura 2 - Campos en los que se emplea la Minería de Datos. Encuesta realizada por KDnuggets, en diciembre de 2008 8. Aprovechando esta tendencia, y las bondades brindadas por las nuevas tecnologías, surge la idea de aplicar técnicas de Minería de Datos a los resultados de una encuesta realizada en la localidad de Jaruco, Provincia Habana, Cuba; a pacientes identificados por el personal médico como diabéticos o con riesgo de padecer la enfermedad. El objetivo de la encuesta fue recopilar la mayor cantidad de información posible, asociada a las características de cada paciente (síntomas, análisis médicos, etc.). El objetivo del análisis mediante técnicas de Minería de Datos es: Obtener modelos que permitan clasificar a un paciente, según los indicadores registrados por la encuesta, en una de las siguientes categorías: Diabético conocido (DC), Diabético detectado (DD), Grupo de no riesgo (GNR), Grupo de riesgo (GR), Tolerancia a la glucosa alterada (TGA), o Alteración de la Glucosa en Ayunas (AGA). Como se planteó anteriormente, el KDD engloba varias fases. Una de las fases concebidas dentro de este proceso, comúnmente denominada “Pre-procesado de datos”, se centra en garantizar la mayor fidelidad y corrección de los datos que se van a emplear como materia prima para los análisis. Múltiples autores coinciden en que la fase de “Pre-procesado de los datos” es la más engorrosa y costosa, en todo proceso de análisis de datos. En el caso particular de la Minería de Datos esta etapa ocupa cerca del 70% del esfuerzo 10. En la Figura 3 se refleja el por ciento de esfuerzo promedio necesario para desarrollar cada una de las fases del KDD.
Figura 3 - Esfuerzo requerido para el desarrollo de cada una de las fases en un proceso de KDD 10. Por la complejidad y lo abarcadora que resulta la etapa de pre-procesado algunos autores la dividen en dos: la “Comprensión de los Datos” y la “Preparación de los datos” 11. Durante la “Comprensión de los datos” se hace una recolección y exploración inicial de los datos para familiarizarse con ellos e identificar problemas de calidad. Además, se trata de descubrir o estimar las relaciones más evidentes para formular las primeras hipótesis sobre información oculta en ellos. La fase de “Preparación de los datos” cubre todas las actividades necesarias para construir la colección de datos que finalmente será minada a partir de la colección inicial de datos. Las tareas asociadas a la preparación de los datos se desarrollan en diferentes ocasiones y no necesariamente siguen un orden prescrito. En el presente trabajo se reflejan los métodos empleados para el desarrollo de la fase de “Pre-procesado de los datos”; y se exponen los principales resultados obtenidos. Dentro de la fase de pre-procesado se hace particular énfasis en la “Compresión de los datos”.
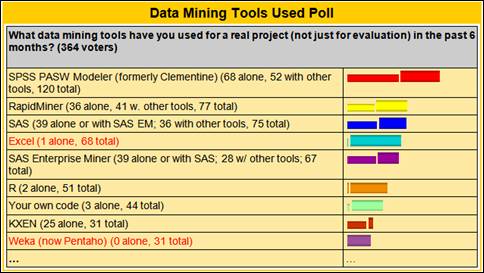
Metodología Como se ha planteado, el proceso de descubrimiento de conocimientos a partir de datos (y en particular la etapa de procesado de los datos) suele ser engorroso y difícil. Con el objetivo de guiar y organizar el trabajo se han desarrollado metodologías y estrategias de trabajo. Dentro de las metodologías que podemos encontrar en la actualidad, la más seguida y referenciada, se nombra CRISP-DM (CRoss Industry Standard Process for Data Mining: Procedimiento Industrial Estándar para realizar Minería de Datos) 11. Esta metodología fue concebida de forma tal que resulte independiente de la herramienta que se utilice para el desarrollo del proyecto; y es de distribución libre, por lo que se encuentra en constante desarrollo por la comunidad internacional. En la Figura 4 se muestran los resultados de una encuesta realizada por el portal para el análisis de datos KDnuggets, en agosto del 2007, sobre las diferentes metodologías empleadas para afrontar procesos de Minería de Datos.
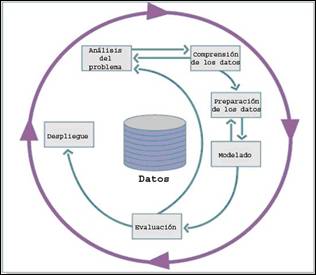
Figura 4 - Principales metodologías empleadas para realizar procesos de KDD según una encuesta realizada por KDnuggets en agosto de 2007. 12 En esta metodología, que consta de seis fases generales: Análisis del problema, Comprensión de los datos, Preparación de los datos, Modelado, Evaluación y Despliegue; el “Pre-procesado de los Datos” está reflejado en la segunda y tercera fases (”Comprensión de los datos” y “Preparación de los datos”). La Figura 5 muestra las principales relaciones que se establecen entre cada una de las fases de la metodología.
Figura 5 - Fases del modelo de referencia CRISP-DM 1.0 y sus principales relaciones 11. Cada una de estas seis macro-fases es descompuesta en un conjunto de tareas generales; donde se especifican además los resultados esenciales que se deben obtener al concluir cada una, y se describe cómo realizarlas. Las ventajas encontradas en esta metodología y el hecho de que sea la más empleada en la actualidad para afrontar procesos de Minería de Datos, unido a que muchas de las restantes se basan en esta (Two Crows 13 y Metodología SQL Server- 2005 14, entre otras); hizo que fuera la elegida para guiar el análisis de las encuestas realizadas con el fin de predecir padecimientos relacionados con la diabetes. Herramienta Para realizar el pre-procesado, los que deseen extraer conocimientos a partir de datos deben, además de contar con una metodología adecuada: apoyarse en herramientas Software que les faciliten la tarea. Para ello se puede emplear todo un arsenal de diversas herramientas. Situémonos en la recopilación inicial de los datos: estos datos pueden provenir de diversas fuentes (digitales o no); entonces entra en acción un conjunto diverso de gestores de bases de datos, o de información digital no necesariamente almacenada en bases de datos, así como de medios para la digitalización de la información. Para las tareas de exploración de datos nos podemos apoyar en Software estadísticos o incluso en el conocido Microsoft Excel (una herramienta muy potente para el análisis de datos, fundamentalmente para la exploración y transformación de estos). Otros Software más específicos para el análisis de datos como Clementine 15, SAS Enterprise Miner 16, o WEKA (Waikato Enviroment for Knowledge Analysis) 17, entre otros; incluyen una serie de prestaciones para importar datos de diversas fuentes digitales o gestores de bases de datos reconocidos. Estas herramientas incorporan además, un conjunto de filtros que permiten realizar las operaciones necesarias para la transformación y limpieza de datos. Muchas permiten incluso la exploración y el filtrado visual de estos. Estas herramientas están designadas específicamente para el análisis de datos mediante el empleo de técnicas de Inteligencia Artificial y algoritmos matemáticos o estadísticos. Durante la fase de Modelado de Datos se vuelve esencial el empleo de alguna de estas. En el caso práctico que se presenta, los datos fueron reflejados por los encuestadores en una hoja de cálculo de Microsoft Excel 2003 que luego se llevó a la versión 2007 18 para utilizar las facilidades para filtrar y transformar datos, así como para la elaborar gráficos que brinda este Software. Este será empleado de conjunto con la Suite WEKA (en su versión 3.5.8). WEKA, desarrollada por un equipo de investigadores de la Universidad de Waikato (Nueva Zelanda), es un entorno de experimentación de análisis de datos desarrollado en Java, constituido por una serie de paquetes de código abierto con diferentes técnicas de preprocesado, clasificación, asociación y visualización. Es en la actualidad una de las herramientas libres para la Minería de Datos de mayor empleo a nivel mundial. A modo de comparación, la Figura 6 presenta el resultado de una encuesta realizada por el portal para el análisis de datos KDnuggets, en mayo del 2009 19 donde se reflejan las herramientas más empleadas.
Figura 6 - Principales herramientas empleadas para el desarrollo de proyectos de Minería de Datos 19.
En este epígrafe se reflejan los principales resultados alcanzados producto del desarrollo de la fase “Comprensión de los datos” propuesta por la metodología CRISP-DM 1.0. Esta macro-fase está subdividida por la metodología en las siguientes tareas generales: “Recopilación inicial de los datos”, “Descripción de los datos”, “Exploración de los datos” y “Verificación de la calidad de los datos”. Recopilación inicial de los datos Como parte del desarrollo de la fase “Recopilación inicial de los datos” se obtuvo un “Reporte de la colección inicial de los datos”. En dicho reporte quedaron reflejadas las fuentes de datos que se emplearán para los futuros análisis, entre las que están las siguientes: los datos colectados reflejan una serie de características presentadas por un grupo de pacientes de la localidad de Jaruco, Provincia Habana, Cuba; los datos se encuentran en una única fuente: un hoja de cálculo de Microsoft Excel 2003; y se tienen registrados los datos correspondientes a 9314 pacientes, de cada paciente se reflejan 63 características. Descripción de los datos El desarrollo de la fase de “Descripción de los datos” permitió la obtención del “Reporte de la descripción de los datos”. El objetivo es familiarizarse con la forma en que se encuentran almacenados los datos y sus características. La descripción refleja aspectos como el formato de los datos, la cantidad, y el tipo de cada uno de los campos. La Tabla 1 muestra un fragmento de la tabla original de 63 campos La tabla puede ser consultada en forma integra en el Anexo 1. Tabla I- Fragmento de la tabla “Descripción de campos”.
Para cada campo la tabla expone:
Exploración de los datos La fase de “Exploración de los datos” aborda las interrogantes del análisis de datos que se pueden solucionar usando consultas, visualización y reportes. Estos análisis pueden responder directamente a los objetivos concretos de investigación o contribuir a una mejor descripción de estos; pueden ayudar a la detección de problemas en la calidad y a formular algunas hipótesis sobre las relaciones entre los datos. Son importantes y reflejan una vista inicial sobre el problema. El “Reporte de la exploración de los datos” obtenido resulta de gran valor para las posteriores fases de la investigación pues en él se detallan las distribuciones que tienen los posibles valores para cada uno de los 31 atributos que se consideró relevante para la investigación. Conociendo la distribución de valores de cada campo es posible una mejor comprensión de los resultados que se obtengan posteriormente durante la fase “Modelado de los datos”. Entre los resultados de interés producto del desarrollo de esta fase podemos citar que se acuerda eliminar de los análisis posteriores al campo “Alteración de Glucosa en Ayuna” pues se pudo observar que el 99.9% de los pacientes dio negativo a este indicador (una distribución tan uniforme de valores no aporta información). La Tabla 2 muestra la distribución de valores para ese campo. Tabla II Distribución de valores para el campo Alteración de Glucosa en Ayunas (AGA)
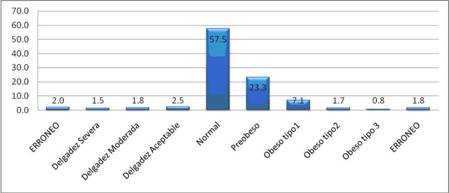
Como ejemplo de las 31 gráficas obtenidas durante el “Reporte de la exploración de los datos” se muestra la Figura 7 que representa la distribución de valores de campo Índice de Masa Corporal (IMC) agrupado según las normas establecidas por la Organización Mundial de la Salud (OMS) 20 .
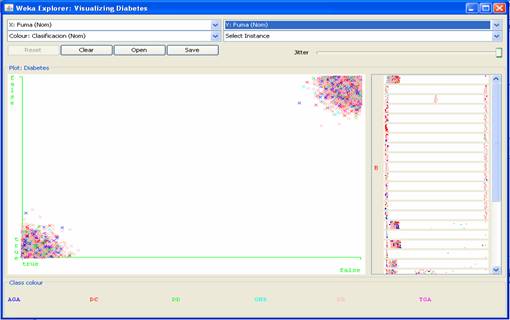
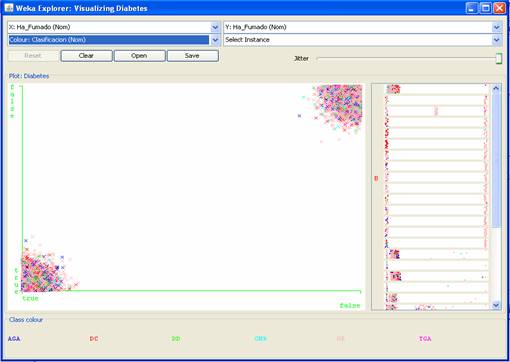
Figura 7 - Distribución de valores para el campo IMC. El valor que se observa en cada una de las barras representa el por ciento de entrevistados que está en esa categoría. Los análisis exploratorios, permiten además, identificar relaciones entre los datos, que formulan las primeras hipótesis sobre relaciones entre ellos y posible conocimiento a obtenerse en la fase de Modelado de Datos. A modo de ejemplo se exponen algunas relaciones que se aprecian mediante la Suite para realizar procesos de KDD: WEKA 3.5.8. Una de las preguntas que las personas frecuentemente se hacen es: ¿fumar puede provocar diabetes? Es por lo tanto uno de los principales atributos a tener en cuenta en nuestros análisis. La Figura 8 muestra una gráfica donde se aprecia que (hasta el punto que en está la investigación), no hay relación entre haber fumado y padecer de diabetes. Puede observarse que no hay predominio de ningún color para los posibles valores del atributo Fumar (true, false). Tampoco se observa diferencia significativa para el atributo Ha Fumado; esta conclusión pudiera parecer trivial luego del análisisprevio, sin embargo es interesante contrastar posibles diferencias entre los fumadores activos y aquellos que han dejado de serlo: Figura 9.
Figura 8 - Relación entre ser fumador activo y ser clasificado por los especialistas médicos en alguna de las siguientes categorías: Diabético conocido (DC), Diabético detectado (DD), Grupo de no riesgo (GNR), Grupo de riesgo (GR), Tolerancia a la glucosa alterada (TGA), o Alteración de la Glucosa en Ayunas (AGA).
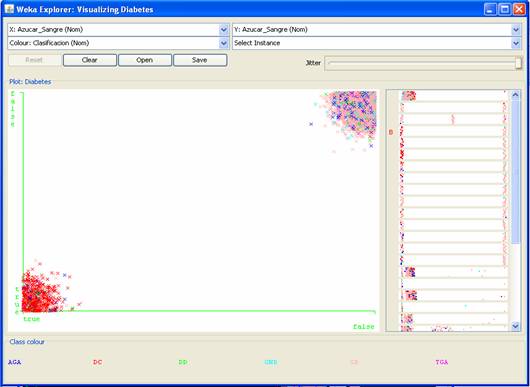
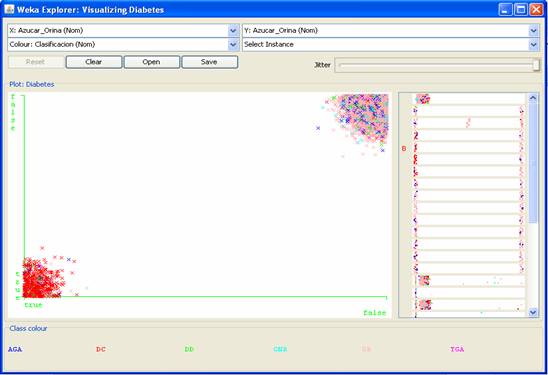
Figura 9 - Relación entre haber sido fumador y ser clasificado por los especialistas médicos en alguna de las siguientes categorías: Diabético conocido (DC), Diabético detectado (DD), Grupo de no riesgo (GNR), Grupo de riesgo (GR), Tolerancia a la glucosa alterada (TGA), o Alteración de la Glucosa en Ayunas (AGA). Otra hipótesis producto de los análisis exploratorios (que tiene amplio aval por parte de los especialistas) es que padecer diabetes está estrechamente relacionado con la cantidad de azúcar en sangre y en orina que posea el paciente. Las figuras 10 y 11 reflejan cómo se comporta la variable objetivo para los atributos citados (los posibles valores para los atributos azúcar en sangre y azúcar en orina son true o false, o sea: si se le detectó o no).
Figura 10 - Relación entre poseer niveles elevados de azúcar en sangre y ser clasificado por los especialistas médicos en alguna de las siguientes categorías: Diabético conocido (DC), Diabético detectado (DD), Grupo de no riesgo (GNR), Grupo de riesgo (GR), Tolerancia a la glucosa alterada (TGA), o Alteración de la Glucosa en Ayunas (AGA).
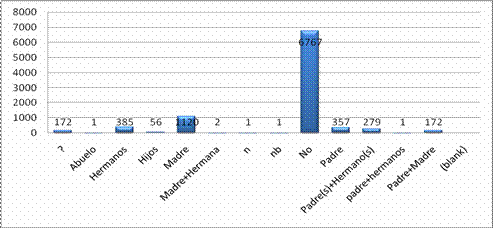
Figura 11 - Relación entre poseer niveles elevados de azúcar en orina y ser clasificado por los especialistas médicos en alguna de las siguientes categorías: Diabético conocido (DC), Diabético detectado (DD), Grupo de no riesgo (GNR), Grupo de riesgo (GR), Tolerancia a la glucosa alterada (TGA), o Alteración de la Glucosa en Ayunas (AGA). Puede observarse que si se detecta azúcar en orina o en sangre existe una alta probabilidad de ser clasificado como Diabético Conocido. Puede incluso inferirse (producto de la representación gráfica) que el poseer el indicador como verdadero para el atributo Azúcar en Orina es más riesgoso que el poseerlo para el atributo Azúcar en Sangre. Verificación de la calidad de los datos El objetivo fundamental de esta tarea es identificar los problemas en la calidad de los datos. Como resultado de esta etapa se obtuvo el “Reporte de la calidad de los datos”, donde se reflejaron los problemas de calidad identificados y las soluciones o medidas a tomar en el caso de los campos e incluso tuplas (entrevistados específicos) que presentas en problemas. Como resultado, se decidió eliminar el campo “Familiares diabéticos” que A Priori resultaba de gran interés pero que reflejó insalvables problemas de calidad. Siempre se ha dicho que la herencia juega un papel fundamental para determinar ciertos tipos de padecimiento, en la diabetes en particular, la experiencia de muchos expertos apunta en esta dirección. La Figura 12 muestra la distribución de valores para el citado atributo. Puede observarse la ocurrencia de valores erróneos como: n o nb por ejemplo; pero este tipo de problema no es el más grave pues dado el poco porciento que representan se pueden eliminar sin mayores consecuencias. El principal problema se encuentra en el solapamiento entre valores, y en la poca ocurrencia de algunas instancias que resulta sospechosa. ¿Cómo es posible que sólo uno de los entrevistados tenga precedencia de abuelo diabético?; el sentido común indica que esto no es lógico. No queda claro tampoco que sean excluyentes las categorías, por ejemplo: MADRE + HERMANA y, HERMANOS o MADRE.
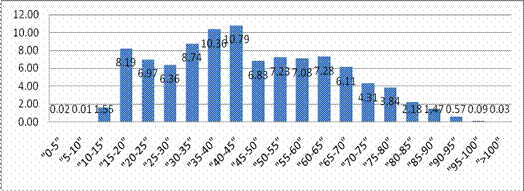
Figura 12- Distribución de valores para el atributo Familiares Diabéticos. En las barras se observa la cantidad neta de individuos pertenecientes a cada posible valor. Otro resultado relevante fue la constatación de que el resto de los atributos presentaban una calidad excelente (ninguno sobrepasa el 5 % de valores erróneos entre valores nulos y fuera de rango). La medida adoptada fue por lo tanto eliminar las tuplas que presentasen problemas en la calidad. La Figura 13 muestra la distribución de valores para el campo edad (en grupos de cinco años), se puede observar que a pesar de la existencia de valores anómalos (se consideran estrictamente anómalos los valores por encima de 100 y por debajo de 5), los valores se mueven en un rango lógico. Sin embargo, se puede observar además que un ínfimo porciento de personas tiene edades por debajo de 15 años y por encima de 90. Para la investigación actual se propone eliminar todos aquellos que estén fuera del citado rango (15-90) pues los menores de 15 son niños; que no poseen iguales características que los adultos, y es sabido que la Diabetes Mellitus es una enfermedad cuyo riesgo de padecimiento aumenta con la edad. Por otra parte, las personas mayores de 90 años de edad son muy pocas afortunadas y los modelos que se obtengan para ellos no tienen valor para la mayoría de la población. Con estos cambios se pierde sólo el 2.27% de los datos. Obsérvese como dato curioso la perfecta distribución normal para los valores y la cola más larga a la derecha, reflejo de que incluso durante las entrevistas no se le dio peso a la población infantil (pues es de suponer que exista un mayor número de personas entre los cero y 15 años de edad que mayores de 80 años).
Figura 13 - Distribución del atributo edad del paciente (en grupos de cinco años). El valor representado en las barras representa el por-ciento de individuos pertenecientes a cada posible valor.
Discusión Al concluir esta iteración del pre-procesado de datos, se tiene una vista minable para enfrentar las próximas etapas de CRISP-DM con 9314 registros y 29 campos: Edad, Sexo, Piel, Estatura, Peso, Índice masa corporal, Circunferencia de Cintura, Azúcar en Sangre, Azúcar en Orina, Diagnosticado Diabético, Síntomas de Diabetes, Antecedentes Cardiopatías y/o Cerebro-Vasculares, Ha fumado, Fuma, Ha consumido Bebidas Alcohólicas, Alcohólico de riesgo, Ha tenido colesterol o triglicéridos altos, Ha padecido de presión alta o hipertensión, Tiene tratamiento con hipotensores, Tensión Arterial Sistólica, Tensión Arterial Diastólica, Tensión Arterial Promedio Sistólica, Tensión Arterial Promedio Diastólica, HDL-Colesterol, Triglicéridos, Glicemia Capilar Ayuna, PTG Ayuna, PTG 2 Horas, Clasificación. Se considera que los resultados alcanzados son alentadores pues la calidad de los datos es buena y se tiene un número considerable de atributos para el análisis. Se pudo establecer las primeras hipótesis sobre relaciones en los datos y tener una vista detallada de los posibles valores por cada campo y sus distribuciones. Con esta vista minable se debe seguir a la próxima fase de la metodología “Modelado de datos” en aras de concretar resultados y obtener las primeras reglas y relaciones explicitas entre estos; producto de la aplicación de técnicas y algoritmos matemáticos. El primer objetivo a ser abordado es determinar la relación entre cada uno de los 28 atributos “independientes” y el atributo objetivo “Clasificación del paciente”, con el fin de encontrar modelos que puedan ser valorados y posteriormente utilizados por médicos y especialistas en este tipo de padecimiento. En un futuro, y en dependencia de los resultados que se obtengan, deberá valorarse la aplicación de las técnicas expuestas a otros conjuntos de datos (relativos a otros grupos de pacientes) y la inclusión de nuevos atributos que permitan una predicción más exacta. La fase que se concluye no es para nada definitiva, pues como bien se pudo observar en la Figura 5, se trata de un proceso iterativo. Este proceso incluye la periódica evaluación de los resultados y la constante vuelta atrás en el desarrollo de cada fase.
El trabajo permitió identificar y describir las características principales de los datos a emplear para clasificar a los pacientes de la localidad de Jaruco. Se logró identificar los atributos relevantes para la investigación, así como los que pueden servir de aval o apoyo a esta. El análisis exploratorio de los datos permitió conocer sus características (distribución, media, valores más frecuentes) lo que resulta de gran valor para comprender el significado de los modelos que se obtengan posteriormente. Se identificaron los problemas de calidad de los datos y se tomaron medidas para tratarlos. Se puede dar por concluida la “Comprensión de los datos” y se puede seguir con las otras fases de la metodología (CRISP-DM 1.0).
A los que creyeron en el proyecto y en las nuevas tecnologías. A los encuestadores que hicieron el, muchas veces injustamente subestimado, trabajo de base.
.
Dirección para correspondenciaDr. Alejandro Rosete Suárez. Anexo 1: Tabla Resumen de la Descripción de los datos.
|